画像生成AI小史
Updated: 2026-06
1. はじめに
授業中に触る Comfy Cloud は、ここ数年の生成AI技術の積み重ねの上にある。本ページはその流れをざっと追う読み物。深入りはしない。各時代の代表的なモデルと、社会で起きた象徴的な事件を一文ずつ把握できれば十分。
なお、本教材で使う Comfy Cloud は、同じ Comfy Org が提供する ComfyUI(自分の PC・GPU にインストールして動かすオープンソース版)をブラウザから使える形にしたクラウドサービス。GPU やモデルの管理は Comfy Org が引き受け、利用者はクレジットを消費してワークフローを実行する。画面・ノード・ワークフローはどちらも共通だが、本教材ではセットアップが要らない Comfy Cloud に絞る。
Comfy Cloud の画面例(Z Image Turbo のテンプレートでテキストから画像を生成しているところ)
2. 黎明期 — ぎこちない生成の時代
2022年以前にも生成AIは存在したが、出力は「夢で見た顔」「うっすら不気味」「破綻した手」が当たり前で、商用ツールには遠かった。
| 年 | 出来事 | 概要 |
|---|---|---|
| 2014 | GAN 論文 | Ian Goodfellow ら、生成器 vs 判別器で学習する枠組みを提案 |
| 2015 | DeepDream(Google) | CNN が「見ている特徴」を強調すると、犬の目玉や渦が増殖する独特の絵に |
| 2017–18 | pix2pix / CycleGAN | 「線画→着色」「馬⇄シマウマ」など画像変換 |
| 2017+ | DeepFake | 動画の顔すり替え技術が公開され、悪用懸念で社会的議論に |
| 2018–19 | StyleGAN / 2(NVIDIA) | 実在しない顔を高解像度で生成。髪・耳に独特の崩れ |
| 2021/01 | DALL·E(OpenAI) | テキスト→画像の初の大規模デモ。低解像度・API 非公開 |
| 2021 | VQGAN+CLIP / Disco Diffusion | Colab で個人に広がる。生成は数十分〜数時間、512px 以下が普通 |
「テキスト1行から数秒で綺麗な絵」は2022年以降の話。それまでは研究室のデモかコミュニティの実験段階だった。

DeepDream(Google, 2015)をモナ・リザに適用した典型例。CNN が学習した「犬の顔」が画面中に増殖する独特のサイケデリック表現。出典: Wikimedia Commons(CC0)

「Edmond de Belamy」(Obvious, 2018)。GAN で生成された肖像画で、2018年にクリスティーズで $432,500 で落札。顔は溶けたように歪み、目鼻立ちが定まらない — 当時の GAN が到達できた「うっすら気持ち悪い」レベルを象徴する作品。出典: Wikimedia Commons(Public domain)
3. 2022年 — 大爆発の夏
画像生成AIが一気に一般に広がった年。
- 2月: Midjourney v1 — Discord ベースのテキスト→画像サービス
- 8月: Stable Diffusion 1.4 — オープンソース公開。手元の GPU で誰でも動かせる
- 9月: Théâtre D’opéra Spatial 事件 — Jason Allen 氏が Midjourney で生成した画像(本セクション末尾の画像)が Colorado State Fair のデジタルアート部門で1位を獲得。「これはアートか」「作者は誰か」という議論が世界中で起きる
Allen 氏のケースは後に米国著作権局(USCO)の判定にも進み、AIが大きな割合で関わった作品の著作権登録を拒否される。2025年に USCO は方針を更新し、「人間の選択・編集・構成といった創作的介入があれば保護対象になりうる」と表明。完全自動生成と人間が深く関わる制作の線引きが今も議論の中心。

Stable Diffusion による生成画像(神社のある森の風景)。出典: Wikimedia Commons

「Théâtre D’opéra Spatial」by Jason Allen (2022, Midjourney) — Colorado State Fair デジタルアート部門優勝作。出典: Wikimedia Commons
4. 2023年 — ノードベース UI と SDXL
- 1月: ComfyUI 公開 — Stable Diffusion のためのノードベース・インターフェース。初心者には複雑だが、内部処理がそのまま画面に出ているため学習教材として優秀
- 7月: SDXL 1.0 — 1024×1024の高解像度生成が可能に。手・顔の破綻が大幅に減る
Web UI(AUTOMATIC1111 など)はチェックボックスとスライダーで構成された「アプリケーション」、ComfyUI は「処理を組み立てるエディタ」。同じ Stable Diffusion を、用途の違う2つのUIで触る時代に入った。


5. 2024年 — 動画生成AI元年
- 2月: Sora 発表(OpenAI) — テキストから1分間のリアルな動画。映像業界に衝撃
- 2月: Stable Diffusion 3 — テキストとの整合がさらに向上
- 下半期: Kling AI — 中国発の動画生成サービスが商用展開
- Flux — Black Forest Labs(Stable Diffusion の元開発チームの一部)が新たな高品質画像モデルをリリース
ここから「画像生成AI」の延長として「動画生成AI」が現実的な制作ツールとして使えるレベルに到達し始める。

6. 2025年 — 動画生成本格化と Aggregator
- 3月: Sora 2 — 品質と速度が大幅に向上、商用利用が広がる
- Hailuo AI — リアルタイム性とアジア系表現に強み、無料枠が比較的広い
- ComfyUI on Cloud — Comfy Cloud が公式提供開始。ローカル GPU を持たなくても触れる
- AI Aggregator という形態の定着 — Pollo.ai のように複数モデルを1つの UI から使えるサービスが普及
複数のサービスが「単独モデル提供」と「Aggregator として複数モデルを束ねる」の2方向に分かれた。Comfy Cloud は前者の系譜だが、Partner Nodes(Sora、Kling、Veo、Nano Banana 等)の経由で他社モデルも呼び出せるハイブリッドになっている。


7. 2026年 現在地
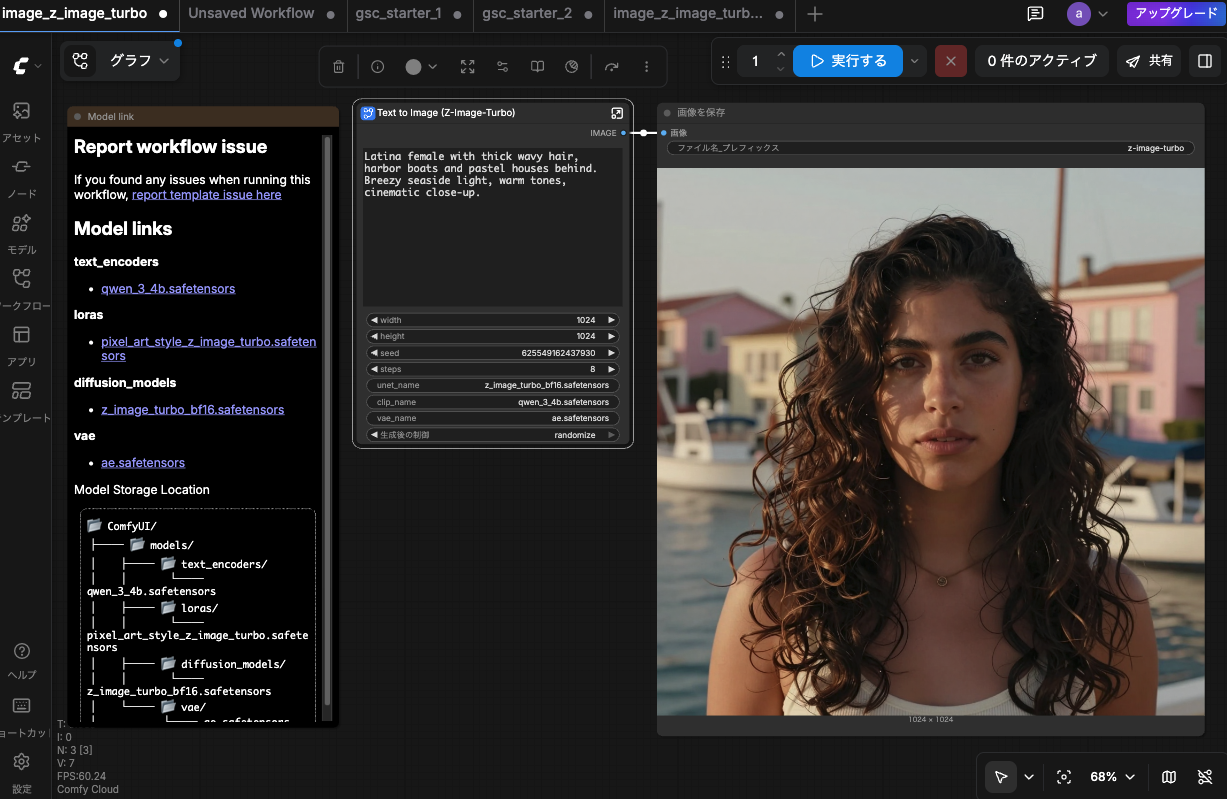
2026年現在、Comfy Cloud で Z Image Turbo を使えば、下のような写実的な画像が無料枠で生成できる(1枚あたり約2クレジット、1024×1024)。
同じプロンプトを 2022 年世代の Stable Diffusion 1.5 で実行すると、解像度の制約も加わって、人物の顔や手は崩れ、背景の質感も粗くなる。4 年弱で写真に見紛うレベルまで進化したことが、同条件の比較で実感できる。
教材で使う Comfy Cloud は、この4年間の積み重ねの「現時点での到達点を、ノードを開けて見られる形」で提供している。授業ではこの「中身が見える」点を最大限活用する。

2026年: Comfy Cloud の Z Image Turbo(1024×1024、約2クレジット)。プロンプト「Latina female with thick wavy hair, harbor boats and pastel houses behind. Breezy seaside light, warm tones, cinematic close-up.」

同じプロンプトを Stable Diffusion 1.5(2022年世代、512×512、約0.3クレジット)で生成したもの。手・顔・背景の質感が大きく違うことが見える