A Short History of Generative AI
Updated: 2026-06
1. Introduction
The Comfy Cloud you interact with during class is built on the advancements in generative AI technology made over the past few years. This page offers a brief overview of that evolution. We won’t go into too much detail. It’s enough to get a basic understanding of the representative models from each era and the symbolic events that occurred in society—just one sentence for each.
Note: this material uses Comfy Cloud. ComfyUI — the open-source version, also from Comfy Org — runs on your own PC (with a GPU). Comfy Cloud is the same software offered as a hosted browser service: Comfy Org manages the GPU and the pre-installed models, and users consume credits to run workflows. The screens, nodes, and workflow patterns are identical in both, but this material focuses on Comfy Cloud since it requires no setup.
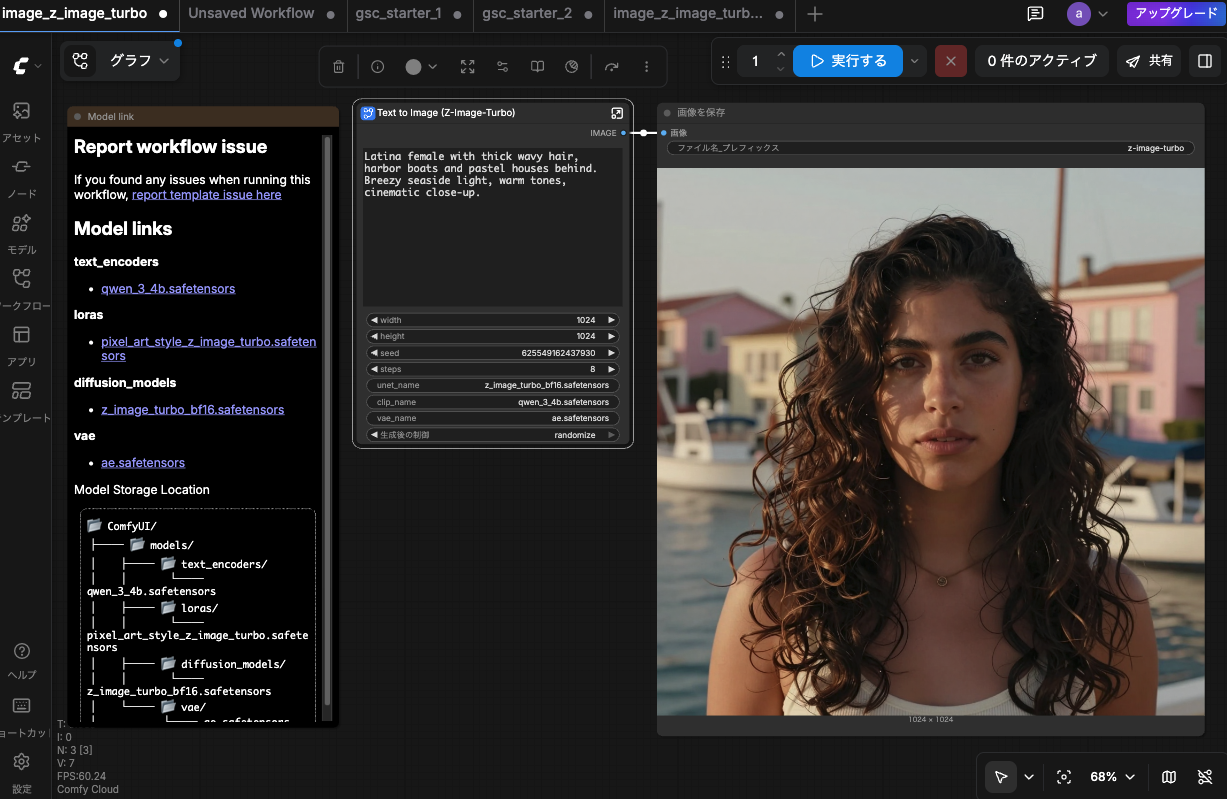
Example of the Comfy Cloud screen (running text-to-image with the Z Image Turbo template)
2. The Dawn Era — Awkward Generation
Image-generation AI existed before 2022, but its output looked like “faces from a dream,” “subtly unsettling,” or “broken hands” — nowhere near commercial-ready.
| Year | Event | Summary |
|---|---|---|
| 2014 | GAN paper | Goodfellow et al. propose training a generator vs. discriminator |
| 2015 | DeepDream (Google) | Amplifying “what a CNN sees” produces multiplying dog eyes and swirls |
| 2017–18 | pix2pix / CycleGAN | Image translation: line art → colorized, horse ↔ zebra |
| 2017+ | DeepFake | Face-swapping in video. Misuse concerns spark social debate |
| 2018–19 | StyleGAN / 2 (NVIDIA) | High-res faces of non-existent people. Hair / ears showed distortions |
| Jan 2021 | DALL·E (OpenAI) | First large-scale text-to-image demo. Low resolution, no public API |
| 2021 | VQGAN+CLIP / Disco Diffusion | Spreads via Colab notebooks. Generation took tens of minutes to hours, ≤512px |
“Type a sentence, get a clean image in seconds” belongs to 2022 and later. Before that, image generation was a research demo or community experiment.

A classic DeepDream example (Google, 2015) applied to the Mona Lisa: the CNN’s learned “dog faces” multiply across the canvas in a signature psychedelic style. Source: Wikimedia Commons (CC0)

“Edmond de Belamy” (Obvious, 2018) — a GAN-generated portrait sold at Christie’s for $432,500 in 2018. The face appears melted and the features fail to resolve, embodying the “subtly unsettling” quality of what GANs could produce at the time. Source: Wikimedia Commons (Public domain)
3. 2022 — The Summer of the Big Bang
The year image-generating AI exploded in popularity.
- February: Midjourney v1 — A Discord-based text-to-image service
- August: Stable Diffusion 1.4 — Released as open source. Anyone can run it on their own GPU
- September: Théâtre D’opéra Spatial Incident — An image generated by Jason Allen using Midjourney (the image at the end of this section) won first place in the digital art category at the Colorado State Fair. This sparked a global debate over whether it was art and who the artist was
Allen’s case eventually reached the U.S. Copyright Office (USCO), which denied copyright registration for works created largely by AI. In 2025, the USCO updated its policy, stating that “works may be eligible for protection if they involve creative human intervention, such as selection, editing, or arrangement.” The distinction between fully automated generation and works involving significant human involvement remains a central point of debate.

Image generated by Stable Diffusion (forest landscape with a Shinto shrine). Source: Wikimedia Commons

“Théâtre D’opéra Spatial” by Jason Allen (2022, Midjourney) — winner of the digital art category at the Colorado State Fair. Source: Wikimedia Commons
4. 2023 — Node-based UI and Improved Model Quality
- January: ComfyUI Released — A node-based interface for Stable Diffusion. While complex for beginners, it’s an excellent learning tool because it displays the internal processing directly on the screen.
- July: SDXL 1.0 — Enables high-resolution generation at 1024×1024. Significantly reduces artifacts in hands and faces.
Web UIs (such as AUTOMATIC1111) are “applications” consisting of checkboxes and sliders, while ComfyUI is an “editor for building processes.” We have entered an era where we can interact with the same Stable Diffusion using two UIs designed for different purposes.


5. 2024 — The First Year of Video-Generating AI
- February: Sora announced (OpenAI) — Realistic one-minute videos generated from text. A game-changer for the video industry
- February: Stable Diffusion 3 — Further improvements in text-image alignment
- Second half of the year: Kling AI — A video generation service from China launches commercially
- Flux — Black Forest Labs (part of the original Stable Diffusion development team) releases a new high-quality image model
From this point on, “video-generating AI”—an extension of “image-generating AI”—will begin to reach a level where it can be used as a practical production tool.

6. 2025 — The Rise of Video Generation and the Emergence of Aggregators
- March: Sora 2 — Significant improvements in quality and speed; commercial adoption expands
- Hailuo AI — Strengths in real-time performance and Asian-style expressions; relatively generous free usage limits
- ComfyUI on Cloud — Comfy Cloud officially launched. Accessible even without a local GPU
- The establishment of the AI Aggregator model — Services like Pollo.ai, which allow users to access multiple models from a single UI, are becoming widespread
Services have generally fallen into two categories: those that offer a single model and those that act as aggregators, bundling multiple models. While Comfy Cloud falls into the former category, it is a hybrid system that can also call upon third-party models via Partner Nodes (such as Sora, Kling, Veo, and Nano Banana).


7. 2026: Current Status
As of 2026, Z Image Turbo on Comfy Cloud’s free tier can produce a near-photorealistic image like the one below (about 2 credits per image, 1024×1024).
The same prompt run on Stable Diffusion 1.5 (2022 generation) — limited to 512×512 — produces results where faces, hands, and background textures are clearly rougher. The side-by-side makes it concrete how far the field has moved in less than four years.
The Comfy Cloud used in our teaching materials presents the culmination of our efforts over the past four years in a format that allows users to open nodes and view their contents. In class, we make the most of this feature that allows students to see what’s inside.

2026: Z Image Turbo on Comfy Cloud (1024×1024, ~2 credits). Prompt: “Latina female with thick wavy hair, harbor boats and pastel houses behind. Breezy seaside light, warm tones, cinematic close-up.”

The same prompt run on Stable Diffusion 1.5 (2022-era model, 512×512, ~0.3 credits). The difference in skin, face, hands, and background texture is immediately visible.